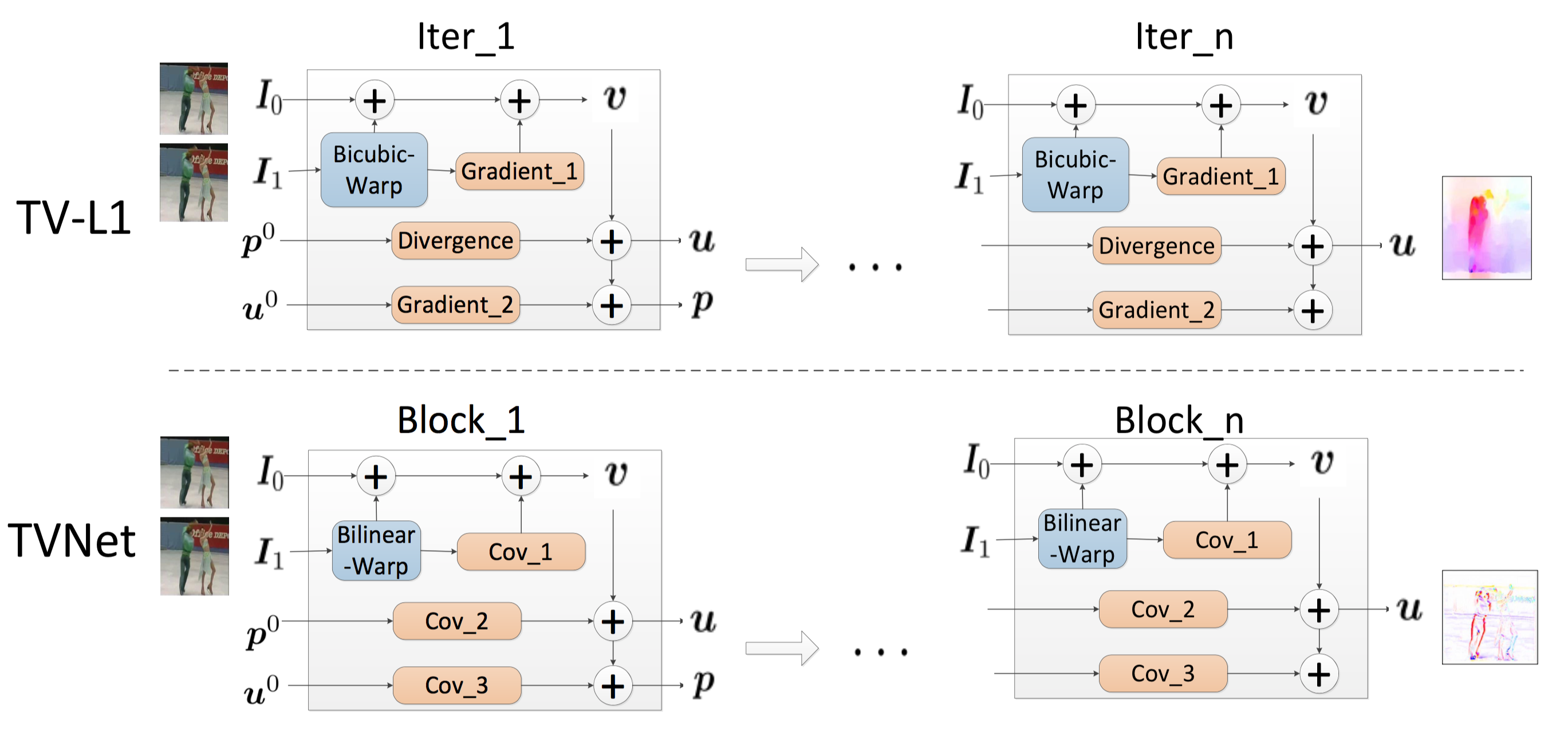
Figure 1: The illustration of the process for unfolding TV-L1 to TVNet. For TV-L1, we illustrate each iteration of TV-L1. We reformulate the bicubic warping, gradient and divergence computations in TV-L1 to bilinear warping and convolution operations in TVNet.
Abstract
Despite the recent success of end-to-end learned representations, hand-crafted optical flow features are still widely used in video analysis tasks. To fill this gap, we propose TVNet, a novel end-to-end trainable neural network to learn optical-flow-like features from data. TVNet subsumes a specific optical flow solver, the TV-L1 method, and is initialized by unfolding its optimization iterations as neural layers.TVNet can therefore be used directly without any extra learning.
Moreover, it can be naturally concatenated with other task-specific networks to formulate an end-to-end architecture, thus making our method more efficient than current multi-stage approaches by avoiding the need to pre-compute and store features on disk. Finally, the parameters of the TVNet can be further fine-tuned by end-to-end training. This enables TVNet to learn richer and task-specific patterns beyond exact optical flow. Extensive experiments on two action recognition and one action similarity detection benchmarks verify the effectiveness of the proposed approach. Our TVNet achieves better accuracies than all compared methods, while being competitive with the fastest counterpart in terms of features extraction time.